前言
使用抖音的分享链接对其进行无水印的下载
对分享链接的网页进行分析,找到跳转的地址,在地址中找到url,请求对应的地址。
对得到的json文件进行分析,找到对应key下的数据下载链接,将其中的关键字替换,playwm替换成play即是完整的下载链接。
代码
下面附上完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| import re
import requests
import os
class DouyinDownload:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/88.0.4324.96'
}
self.windows_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
def check_url(self, url):
response = requests.get(url=url, headers=self.windows_headers, allow_redirects=False)
if response.headers.get('location'):
return response.headers.get('location')
else:
print('解析失败')
def download(self, url):
response = requests.get(url=url, headers=self.windows_headers).json()
v_title = response['item_list'][0]['share_info']['share_title']
download_url = response['item_list'][0]['video']['play_addr']['url_list'][0].replace("playwm", "play")
path = 'F:\Spider\douyin'
data = requests.get(url=download_url, headers=self.headers).content
with open(path + '/{}.mp4'.format(v_title), 'wb') as video:
video.write(data)
print("视频名:{}\n状态: 下载完成\n地址:{}".format(v_title, path))
open_status = input("是否打开? y/n\n")
if open_status == 'y' or 'Y':
os.startfile(path)
else:
pass
def run(self):
share_url = input("请输入抖音分享链接:")
share_url = re.findall(r'https://v.douyin.com/.*?/', share_url)[0]
location = self.check_url(share_url)
v_id = re.findall('/share/video/(\d*)', location)[0]
download_url = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={}'.format(v_id)
self.download(download_url)
if __name__ == '__main__':
dy = DouyinDownload()
dy.run()
|
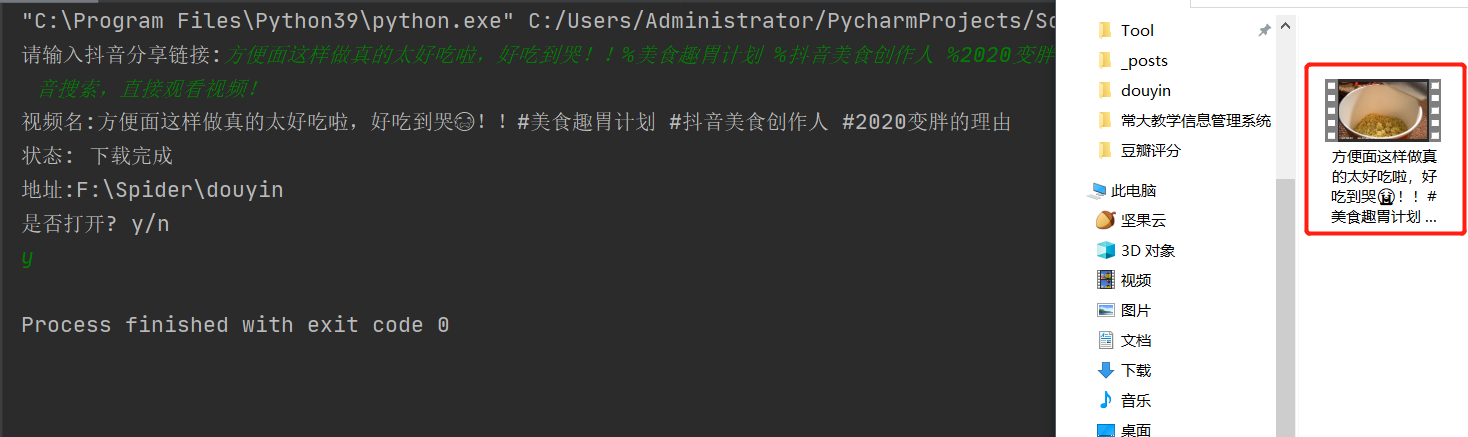
运行截图