1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
|
import requests
from lxml import etree
import pandas as pd
from wordcloud import WordCloud
import jieba
import datetime
class BarrageSpider:
def __init__(self, bv):
self.bv = bv
self.video_name = None
self.barrage_url = 'https://comment.bilibili.com/{}.xml'
self.date_url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid={}&date={}'
self.index_url = 'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={}&month={}'
self.bv_url = 'https://api.bilibili.com/x/player/pagelist?bvid=' + bv + '&jsonp=jsonp'
self.video_url = 'https://www.bilibili.com/video/{}'.format(bv)
self.comment = {
'referer': 'https://www.bilibili.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66 '
}
self.date_headers = {
"referer": "https://www.bilibili.com/",
"origin": "https://www.bilibili.com",
"cookie": "你的cookie 爬很久远的视频 会被封ip 后面接收到的都是空结果",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66 "
}
def get_cid(self):
return requests.get(url=self.bv_url, headers=self.comment).json()['data'][0]['cid']
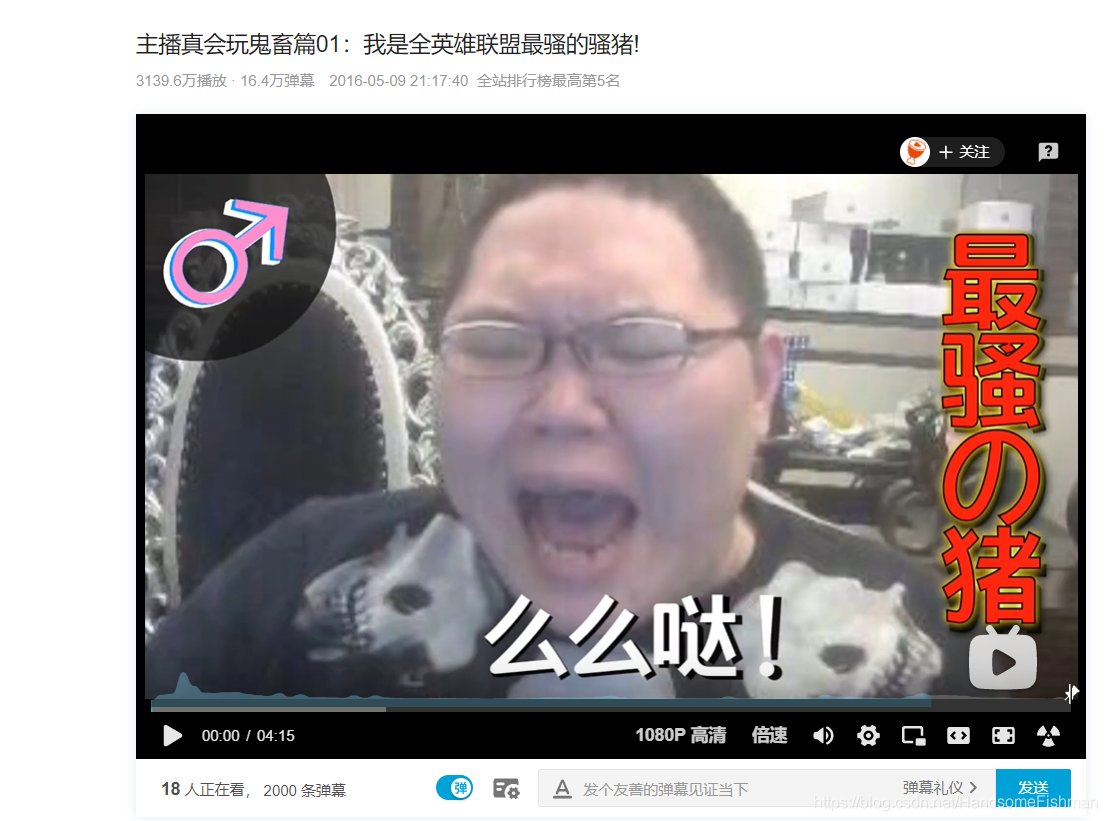
def get_video_time(self):
time_data = requests.get(url=self.video_url, headers=self.comment).text
video_page = etree.HTML(time_data)
v_time = video_page.xpath('//div[@class="video-data"]/span[3]/text()')[0].split(' ')[0]
self.video_name = video_page.xpath('//h1[@class="video-title"]/span/text()')[0]
return v_time
def parse_url(self):
cid = self.get_cid()
response = requests.get(url=self.barrage_url.format(cid), headers=self.comment).content
data = etree.HTML(response)
barrage_list = data.xpath('//d')
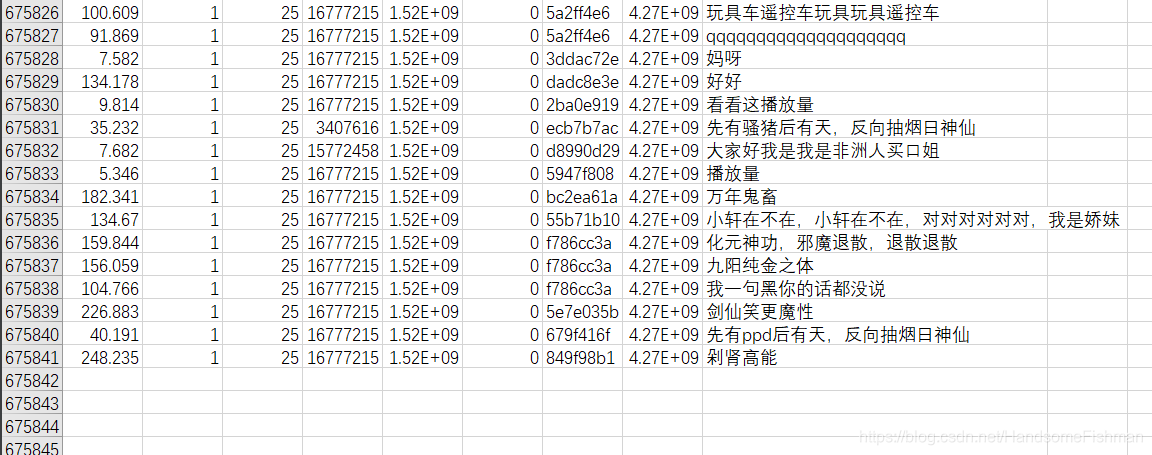
for barrage in barrage_list:
info = barrage.xpath('./@p')[0].split(',')
content = barrage.xpath('./text()')[0]
item = {'出现时间': info[0], '弹幕模式': info[1], '字体大小': info[2], '颜色': info[3], '发送时间': info[4], '弹幕池': info[5],
'用户ID': info[6], 'rowID': info[7], '内容': content}
print(item)
def parse_date_url(self, month):
print('正在爬取{}月份的数据'.format(month))
result = []
oid = self.get_cid()
date_by_month = requests.get(url=self.index_url.format(oid, month), headers=self.date_headers).json().get(
'data')
if date_by_month:
for day in date_by_month:
print('{}月份数据下的{}'.format(month, day))
date_page = requests.get(url=self.date_url.format(oid, day), headers=self.date_headers).content
date_data = etree.HTML(date_page)
barrage_list = date_data.xpath('//d')
for barrage in barrage_list:
things = barrage.xpath('./@p')[0].split(',')
content = barrage.xpath('./text()')[0].replace(" ", "")
item = {'出现时间': things[0], '弹幕模式': things[1], '字体大小': things[2], '颜色': things[3], '发送时间': things[4],
'弹幕池': things[5],
'用户ID': things[6], 'rowID': things[7], '内容': content}
result.append(item)
return result
def parse_month(self):
start_day = datetime.datetime.strptime(self.get_video_time(), '%Y-%m-%d')
end_day = datetime.date.today()
months = (end_day.year - start_day.year) * 12 + end_day.month - start_day.month
m_list = []
for mon in range(start_day.month - 1, start_day.month + months):
if (mon % 12 + 1) < 10:
m_list.append('{}-0{}'.format(start_day.year + mon // 12, mon % 12 + 1))
else:
m_list.append('{}-{}'.format(start_day.year + mon // 12, mon % 12 + 1))
return m_list
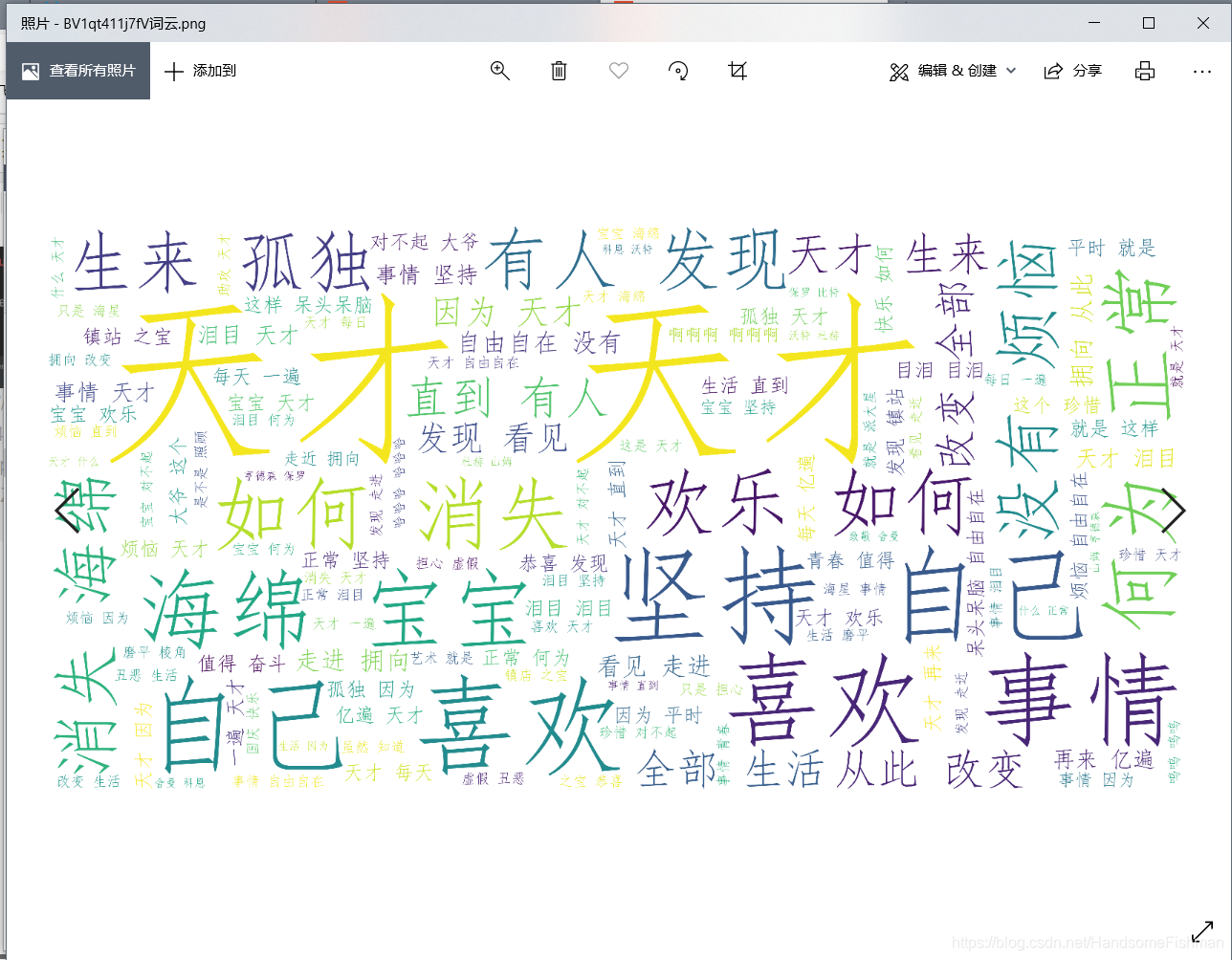
def wordCloud(self):
WordCloud(font_path="C:/Windows/Fonts/simfang.ttf", background_color='white', scale=16).generate(" ".join(
[c for c in jieba.cut("".join(str((pd.read_csv('{}弹幕池数据集.csv'.format(self.video_name))['内容']).tolist()))) if
len(c) > 1])).to_file(
"{}词云.png".format(self.video_name))
if __name__ == '__main__':
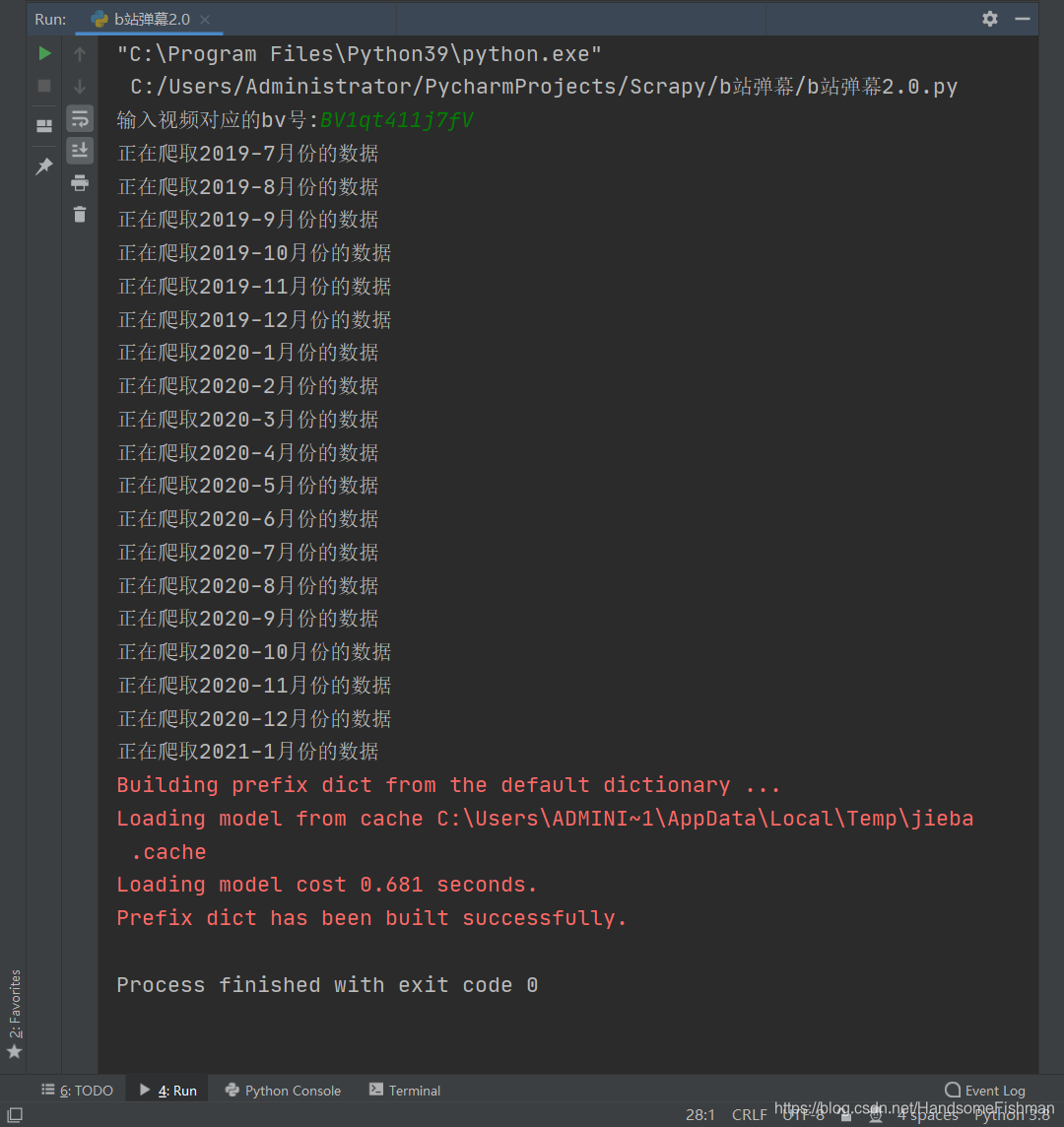
bv_id = input('输入视频对应的bv号:')
spider = BarrageSpider(bv_id)
spider.parse_month()
word_data = []
months = spider.parse_month()
for month in months:
word = spider.parse_date_url(month)
word_data.extend(word)
data = pd.DataFrame(word_data)
data.drop_duplicates(subset=['rowID'], keep='first')
data.to_csv('{}弹幕池数据集.csv'.format(spider.video_name), index=False, encoding='utf-8-sig')
spider.wordCloud()
|