爬取链家的二手房信息,存储到数据库方便以后查看
页面分析
分析页面后发现是前后端未分离的状态,所以需要使用xpath分析界面元素
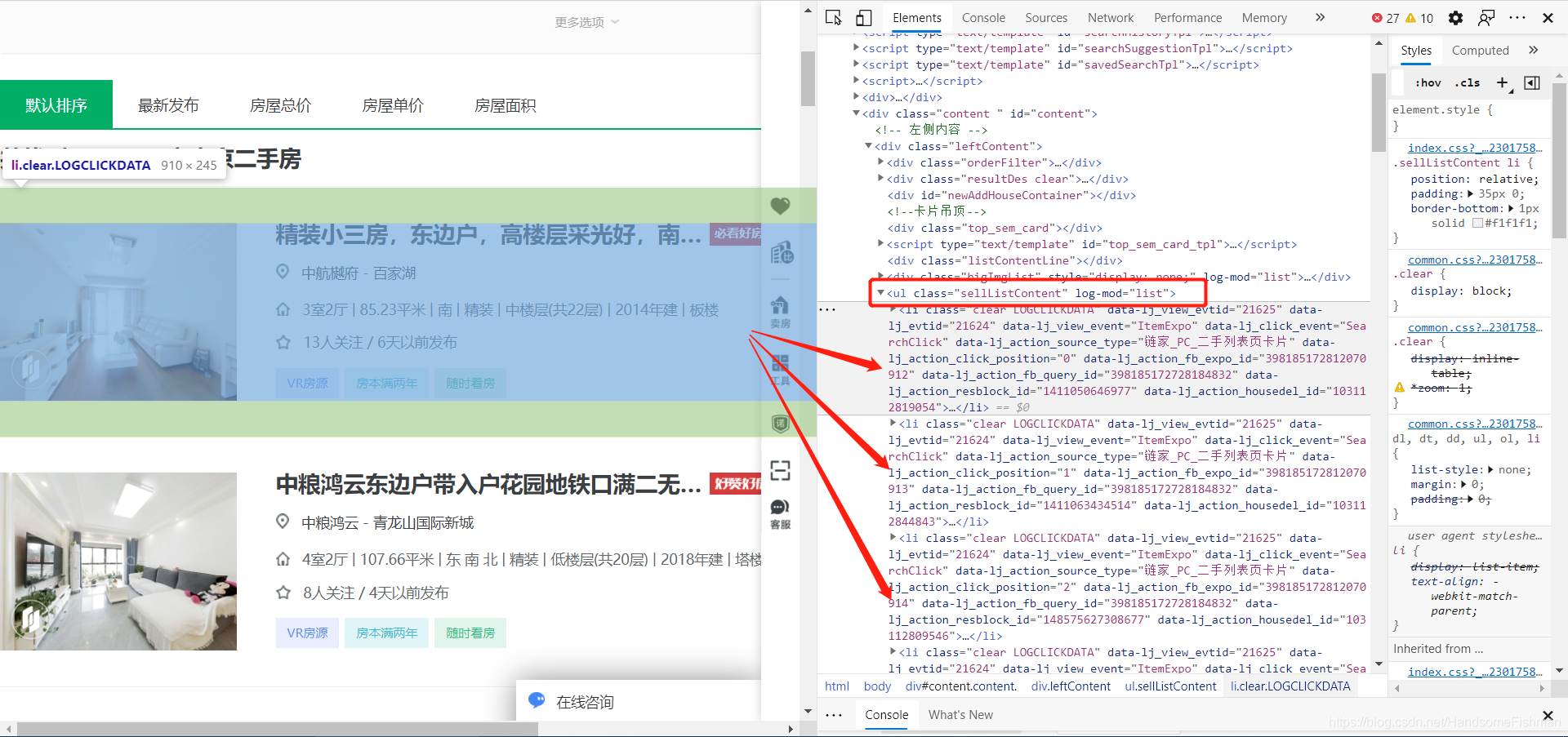
在li中存放着对应的div,有相关的信息:
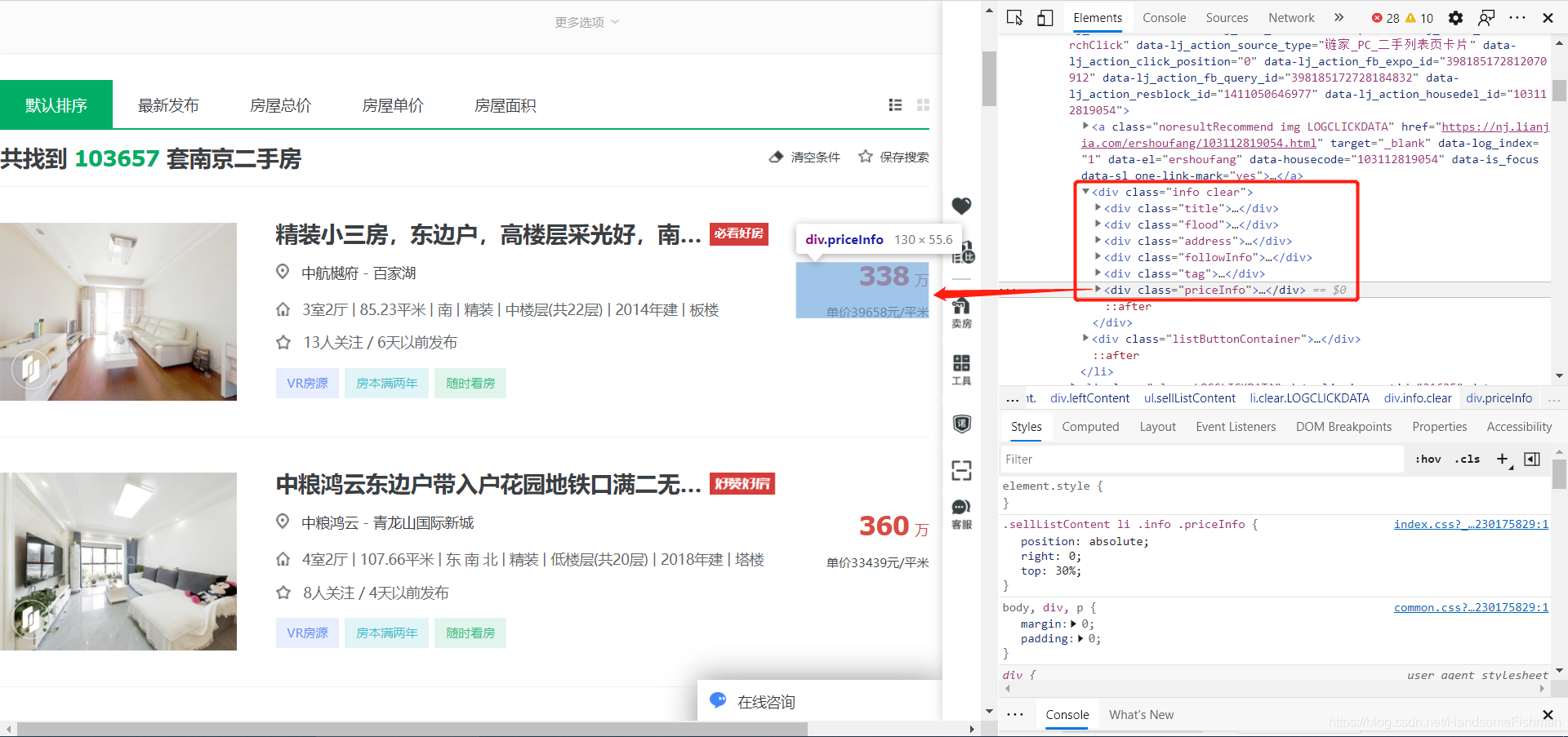
分析请求链接:
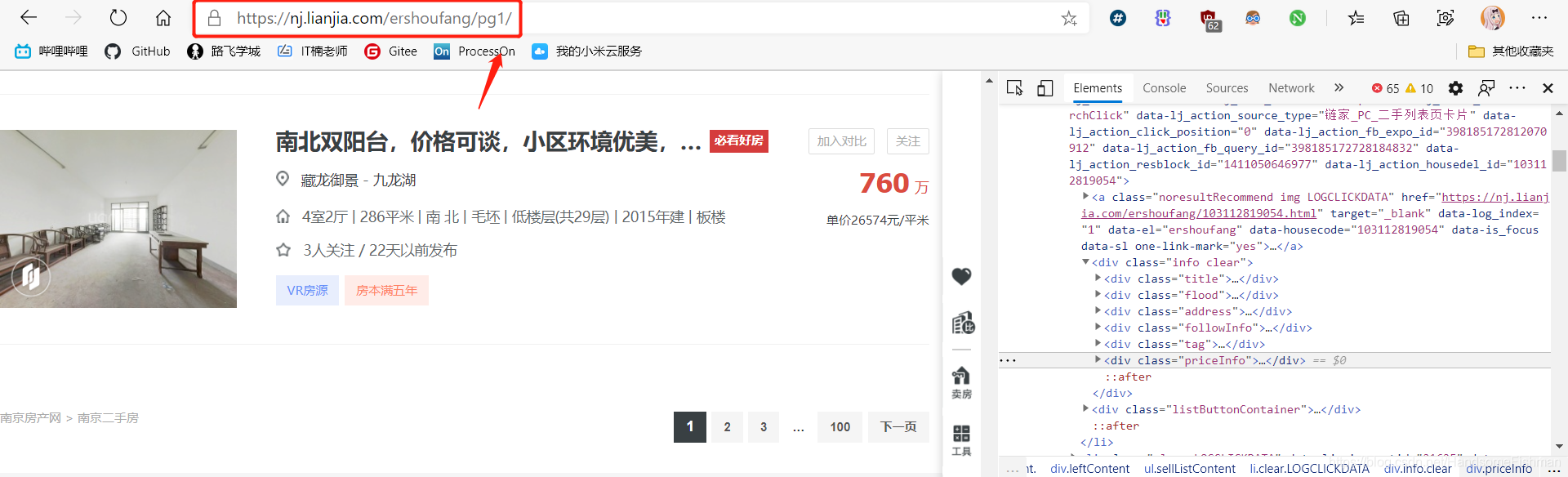
只需要更改pg后面的数字即可,页面分析完毕。
提示:以下是本篇文章正文内容,下面案例可供参考
引入库
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| from lxml import etree
from fake_useragent import UserAgent
import requests
import random
import pymysql
proxy_pool = [{'HTTP': '175.43.151.3:9999'}, {'HTTP': '220.249.149.140:9999'}, {'HTTP': '175.44.108.206:9999'},
{'HTTP': '120.83.101.115:9999'}, {'HTTP': '175.42.122.233:9999'}, {'HTTP': '60.13.42.107:9999'},
{'HTTP': '113.195.152.127:9999'}, {'HTTP': '36.248.133.196:9999'}, {'HTTP': '120.83.105.95:9999'},
{'HTTP': '112.111.217.160:9999'}, {'HTTP': '171.12.221.158:9999'}, {'HTTP': '113.121.72.221:9999'}]
headers = {
'Host': 'nj.lianjia.com',
'User-Agent': UserAgent().random
}
conn = pymysql.Connect(host='localhost', port=3306, user='用户名',
password='数据库密码', db='对应数据库', charset='utf8')
|
方法编写
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| def get_page(url):
response = requests.get(url=url, headers=headers, proxies=random.choice(proxy_pool)).text
parse_data = etree.HTML(response)
li_list = parse_data.xpath('//ul[@class="sellListContent"]/li')
for li in li_list:
title = li.xpath('./div[@class="info clear"]/div[@class="title"]/a/text()')[0]
flood = li.xpath('./div[@class="info clear"]/div[@class="flood"]/div[@class="positionInfo"]/a[1]/text()')[0] + \
'- ' + \
li.xpath('./div[@class="info clear"]/div[@class="flood"]/div[@class="positionInfo"]/a[2]/text()')[0]
address = li.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="houseInfo"]/text()')[0]
followInfo = li.xpath('./div[@class="info clear"]/div[@class="followInfo"]/text()')[0]
totalPrice = li.xpath('./div[@class="info clear"]/div[@class="priceInfo"]/div[@class="totalPrice"]/span['
'1]/text()')[0] + '万'
unitPrice = li.xpath('./div[@class="info clear"]/div[@class="priceInfo"]/div[@class="unitPrice"]/span[1]/text()')[0]
sql = 'insert into lianjia(title, flood, address, followInfo,totalPrice, unitPrice) ' \
'values ("{}", "{}", "{}", "{}", "{}", "{}")'.format(title, flood, address, followInfo, totalPrice, unitPrice)
cursor = conn.cursor()
try:
cursor.execute(sql)
conn.commit()
except Exception as e:
print(e)
conn.rollback()
|
主函数编写
代码如下:
1
2
3
4
5
6
7
8
9
| if __name__ == '__main__':
base_url = 'https://nj.lianjia.com/ershoufang/pg{}/'
for i in range(1, 101):
get_page(base_url.format(i))
print('正在存储第{}条'.format(i) + '....')
conn.close()
|
运行结果
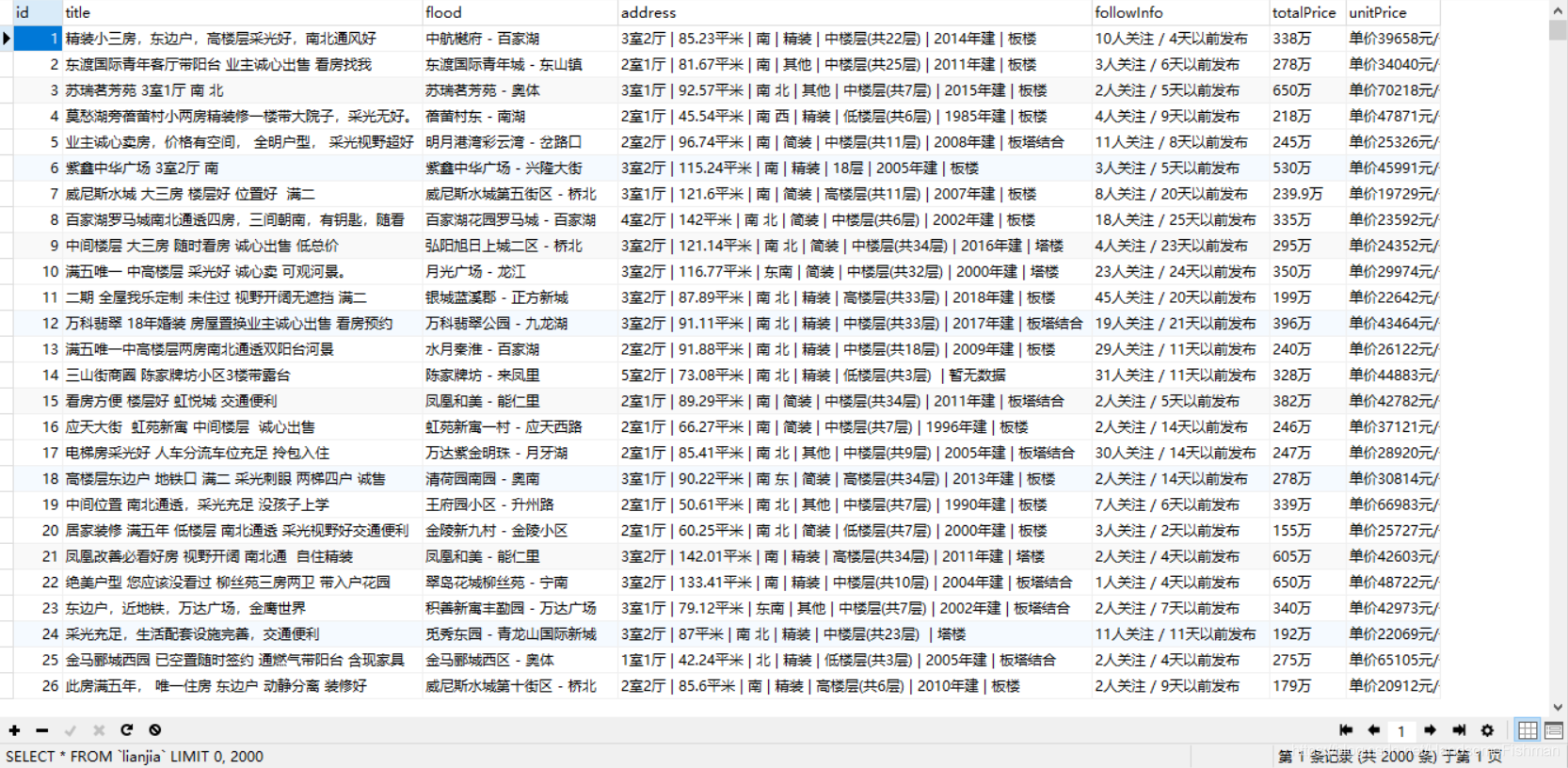
对其进行条件查找,找出自己想要的数据:
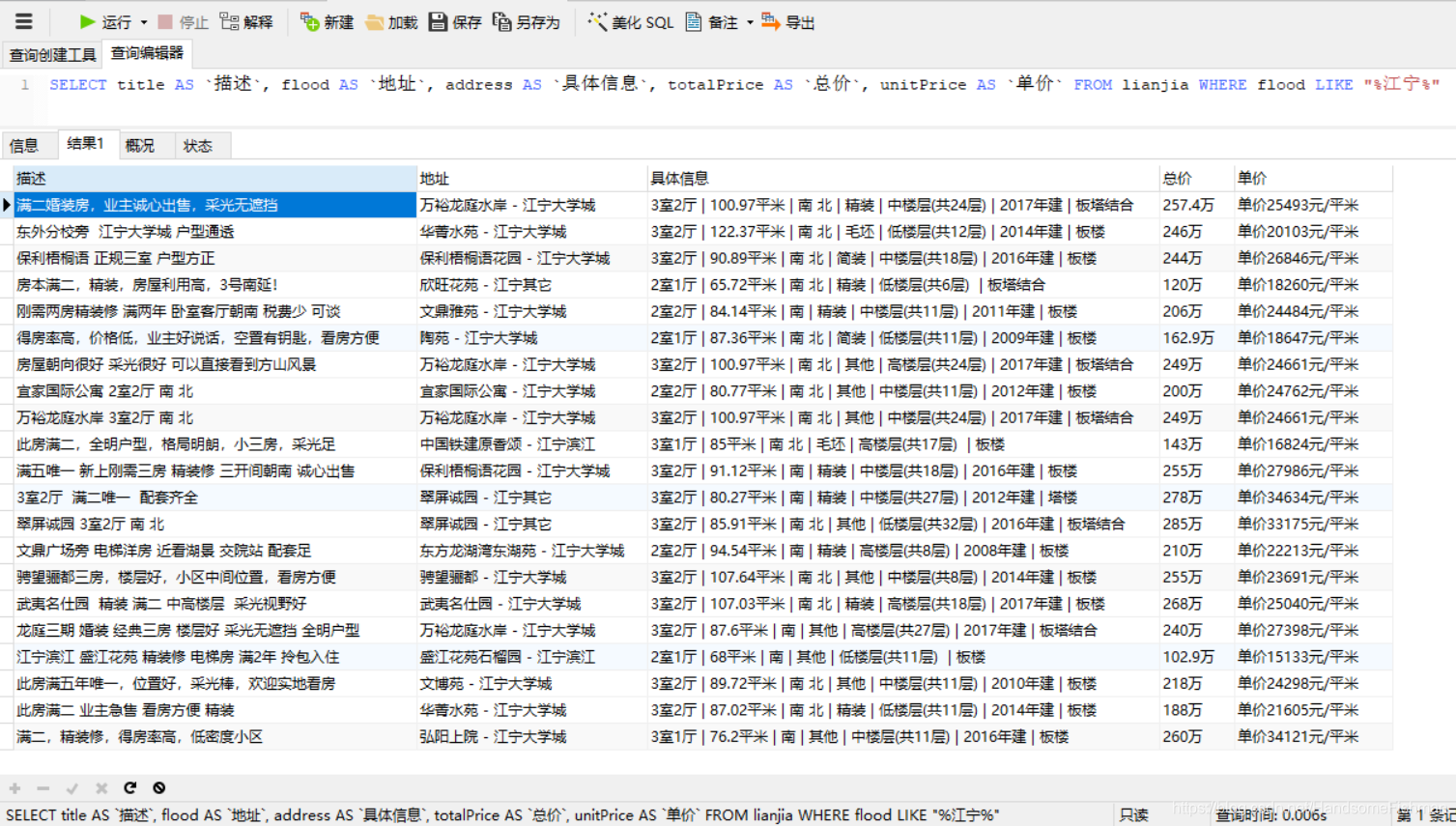
注:案例仅供学习