侵权删除。
前言
今天准备在网上找一个web模板,用来做Echarts的数据可视化。寻找模板的过程中像往常一样,遇到了很多的收费网站,一般都是月费年费类型的。然后我就遇到了下面这个网站:

在我下载的过程中简单分析了一下,是否可以抓包的方式,获取对应的下载链接,下面进入我们的正文分析环节。
以下是本篇文章正文内容
一、页面分析

发现下载模板的a标签中没有存在相应的href属性,一般下载链接都不会放在这,应该是通过js进行的控制。于是我看了一下下载好模板对应的url链接,对其进行分析后发现,几个url大致相同,只有两个参数发生了变化,就是对应的压缩文件名,和对应的sid。
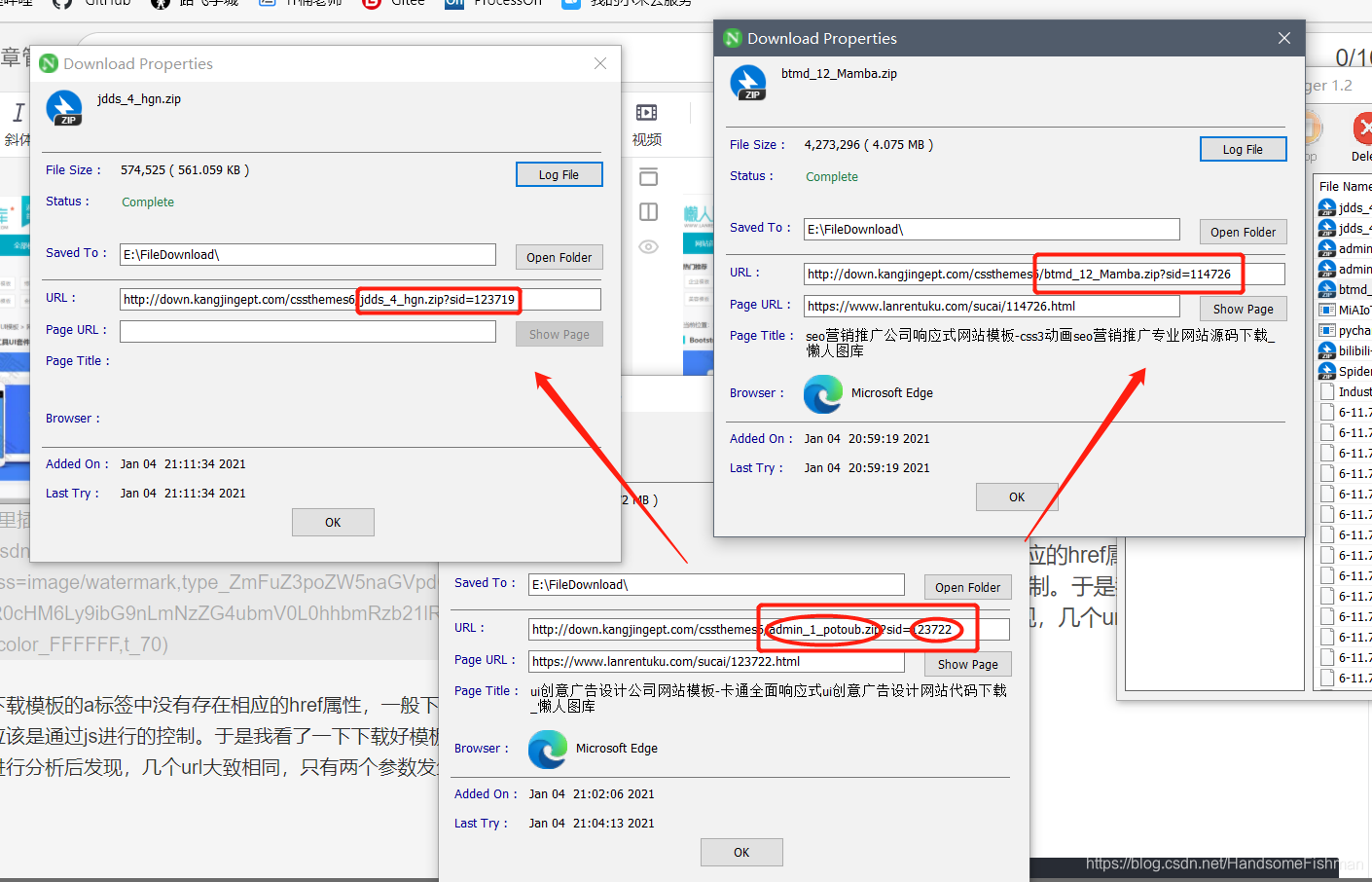
我们可以发现 第一个压缩包名字就是在线预览url中,index.html之前的参数,所以我们直接取页面中href属性值就可以,sid页面上则贴心的给我们显示出来了,就是素材编号,猜测sid的s就是素材的缩写,hhh
再看看我们点击下载按钮后的抓包工具里,出现了一个异步请求,又是cookie又是token的校验。

最后返回了一个json数据,里面果然存放的就是下载链接等信息。
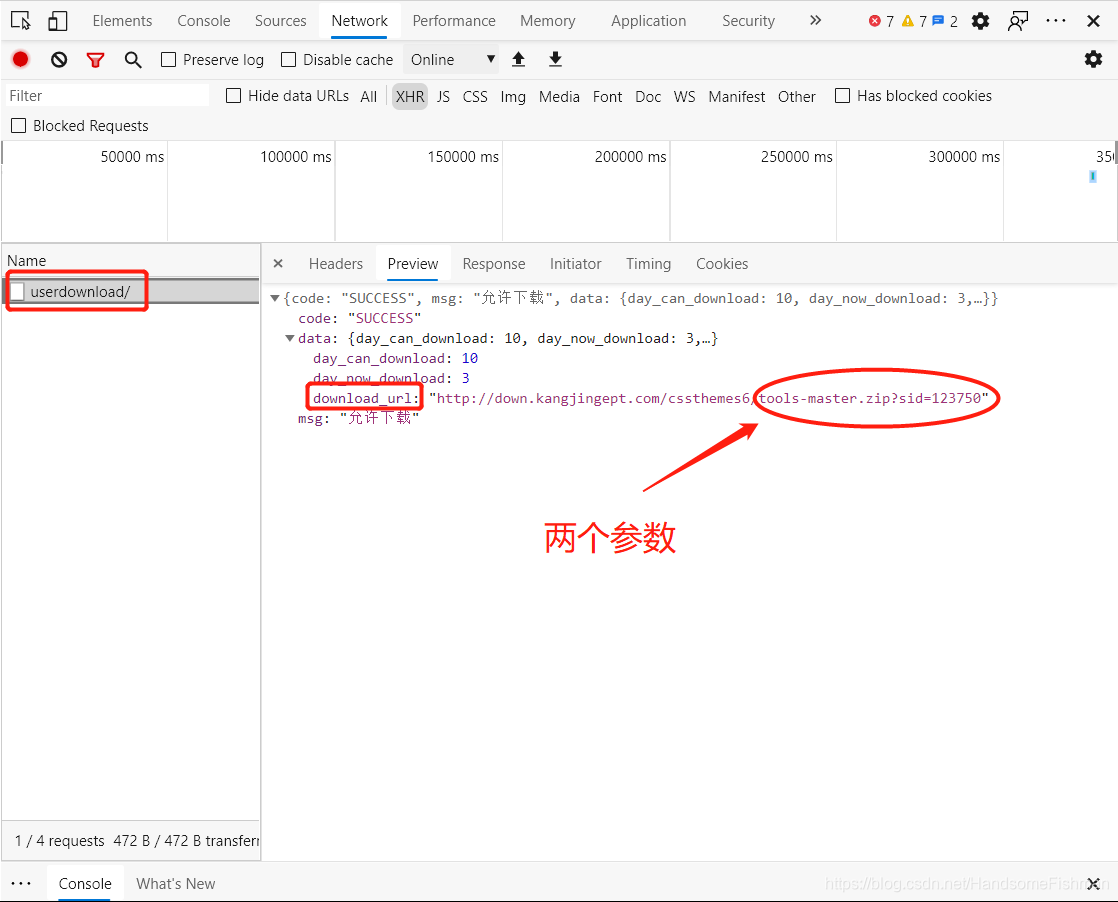
到这里我们的分析基本已经结束了,拿到了下载链接后,打开浏览器的隐私窗口对其进行访问,果然不用登陆就直接下载了对应的模板压缩包,接下来进行我们的代码编写。
二、编写代码
代码很简短,这次主要是锻炼我们的网页分析和抓包思路。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import requests
import random
from fake_useragent import UserAgent
from lxml import etree
proxy_pool = [{'http': 'http://175.42.122.247:9999'}, {'http': 'http://115.53.37.35:9999'},
{'http': 'http://115.221.242.62:9999'}, {'http': 'http://175.42.129.10:9999'}]
headers = {
'user-agent': UserAgent().random
}
base_url = 'http://down.kangjingept.com/cssthemes6/{}.zip?sid={}'
def get_zip(url):
sid = url.split('/')[-1].split('.')[0]
response = requests.get(url=url, headers=headers, proxies=random.choice(proxy_pool)).text
data = etree.HTML(response)
zip_name = data.xpath('//div[@class="btn_box"]/a[1]/@href')[0].split('/')[-2]
file_name = data.xpath('/html/body/div[8]/h1/text()')[0]
zip_url = base_url.format(zip_name, sid)
zip_content = requests.get(url=zip_url, headers=headers).content
with open('./{}.zip'.format(file_name), 'wb') as z:
z.write(zip_content)
print('文件{}.zip 下载完毕!!!'.format(file_name))
input_url = input('请输入对应的链接:')
get_zip(input_url)
|
结果演示