1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| import requests
from lxml import etree
from fake_useragent import UserAgent
import random
import pymysql
proxy_pool = [{'HTTP': '112.84.53.165:9999'}, {'HTTP': '171.35.169.58:9999'}, {'HTTP': '49.86.180.142:9999'},
{'HTTP': '113.194.131.190:9999'}, {'HTTP': '110.243.22.233:9999'}, {'HTTP': '123.169.163.99:9999'},
{'HTTP': '123.163.117.140:9999'}, {'HTTP': '113.195.20.166:9999'}, {'HTTP': '114.235.23.237:9000'},
{'HTTP': '202.109.157.64:9000'}, {'HTTP': '171.35.175.31:9999'}, {'HTTP': '113.195.168.235:9999'},
{'HTTP': '125.108.75.135:9000'}, {'HTTP': '123.101.237.3:9999'}, {'HTTP': '139.155.41.15:8118'},
{'HTTP': '118.212.104.240:9999'}]
headers = {
'Referer': 'https://nj.fang.lianjia.com/',
'User-Agent': UserAgent().random
}
if __name__ == '__main__':
print('打开数据库...')
conn = pymysql.Connect(host='localhost', port=3306, user='root',
password='', db='spider', charset='utf8')
base_url = 'https://nj.fang.lianjia.com/loupan/pg{}/'
data = []
print('初始化数据...')
for i in range(1, 86):
data.append(base_url.format(i))
print('开始爬取...')
for url in data:
response = requests.get(url=url, headers=headers, proxies=random.choice(proxy_pool))
res_data = etree.HTML(response.content.decode())
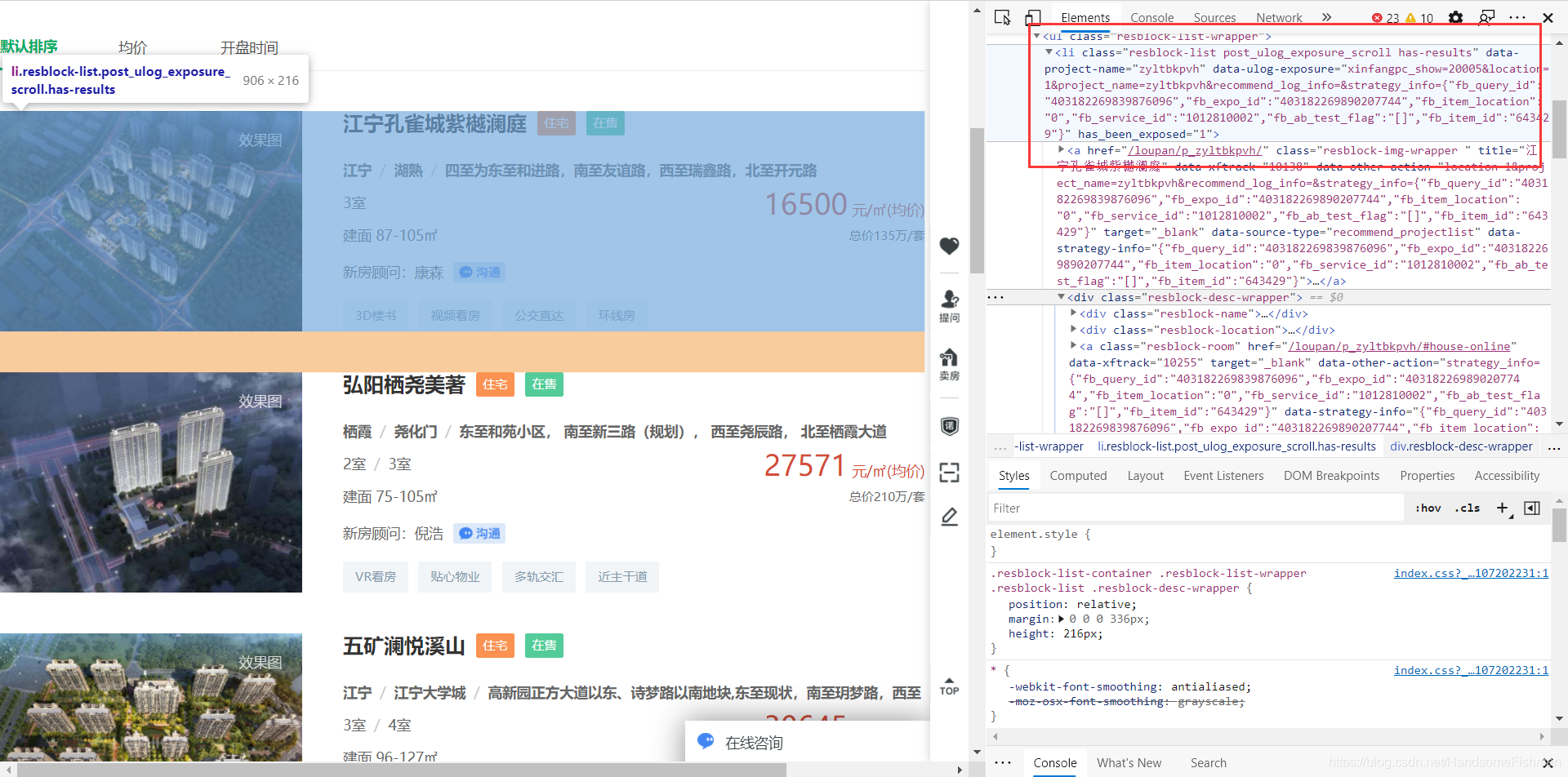
lis = res_data.xpath('//li[@class="resblock-list post_ulog_exposure_scroll has-results"]')
for li in lis:
img_url = li.xpath('./a/img/@data-original')[0].split('.592x432.jpg')[0]
name = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-name"]/a[1]/text()')[0]
resblock_type = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-name"]/span[1]/text()')[0]
sale_status = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-name"]/span[2]/text()')[0]
area = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/span[1]/text()')[0]
location = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/span[1]/text()')[0] + '/' + \
li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/span[2]/text()')[0] + '/' + \
li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/a[1]/text()')[0]
resblock_room = li.xpath('./div[@class="resblock-desc-wrapper"]/a[@class="resblock-room"]/span[1]/text()')
if resblock_room:
resblock_room = resblock_room[0]
else:
resblock_room = '暂无信息'
resblock_area = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-area"]/span[1]/text()')
if resblock_area:
resblock_area = resblock_area[0]
else:
resblock_area = '暂无信息'
main_price = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-price"]/div[@class="main-price"]/span[@class="number"]/text()')[0]
second = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-price"]/div[@class="second"]/text()')
if second:
second = second[0]
else:
second = '暂无信息'
sql = 'insert into xinfang(name, resblock_type, sale_status, area, location, resblock_room, resblock_area, main_price, second, img_url) values ("{}", "{}", "{}", "{}", "{}", "{}", "{}", "{}", "{}", "{}")'.format(
name, resblock_type, sale_status, area, location, resblock_room, resblock_area, main_price, second,
img_url)
cursor = conn.cursor()
try:
cursor.execute(sql)
conn.commit()
except Exception as e:
print(e)
conn.rollback()
print('爬取结束关闭数据库...')
conn.close()
|