微博个人主页的信息爬取
闲话少说,先进入分析过程。
因为相对而言移动端的界面会比较好爬取,所以今天我们爬取移动端微博的页面,如下:
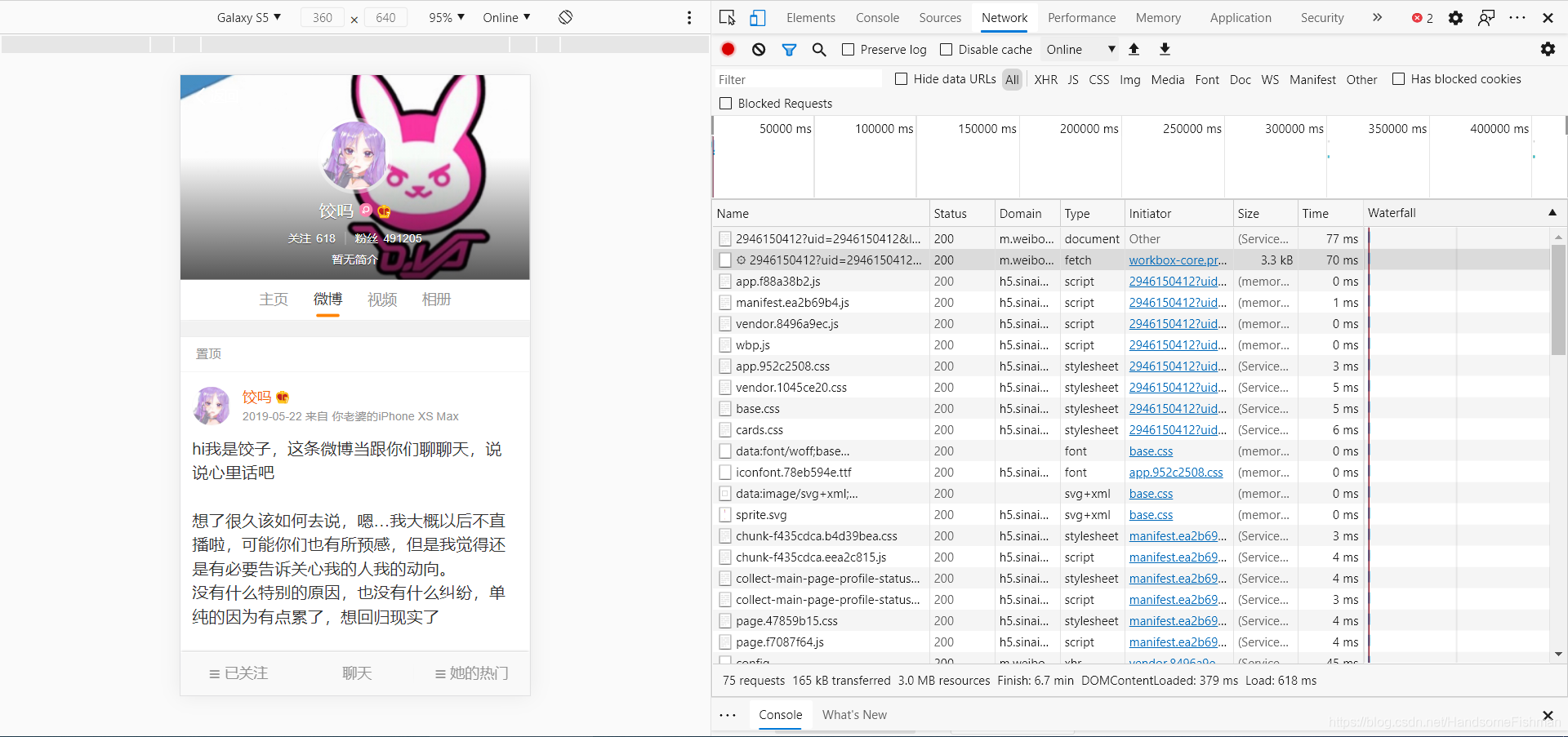
这里是前后端分离异步加载的数据,所以我们去抓包工具下寻找对应的接口地址:
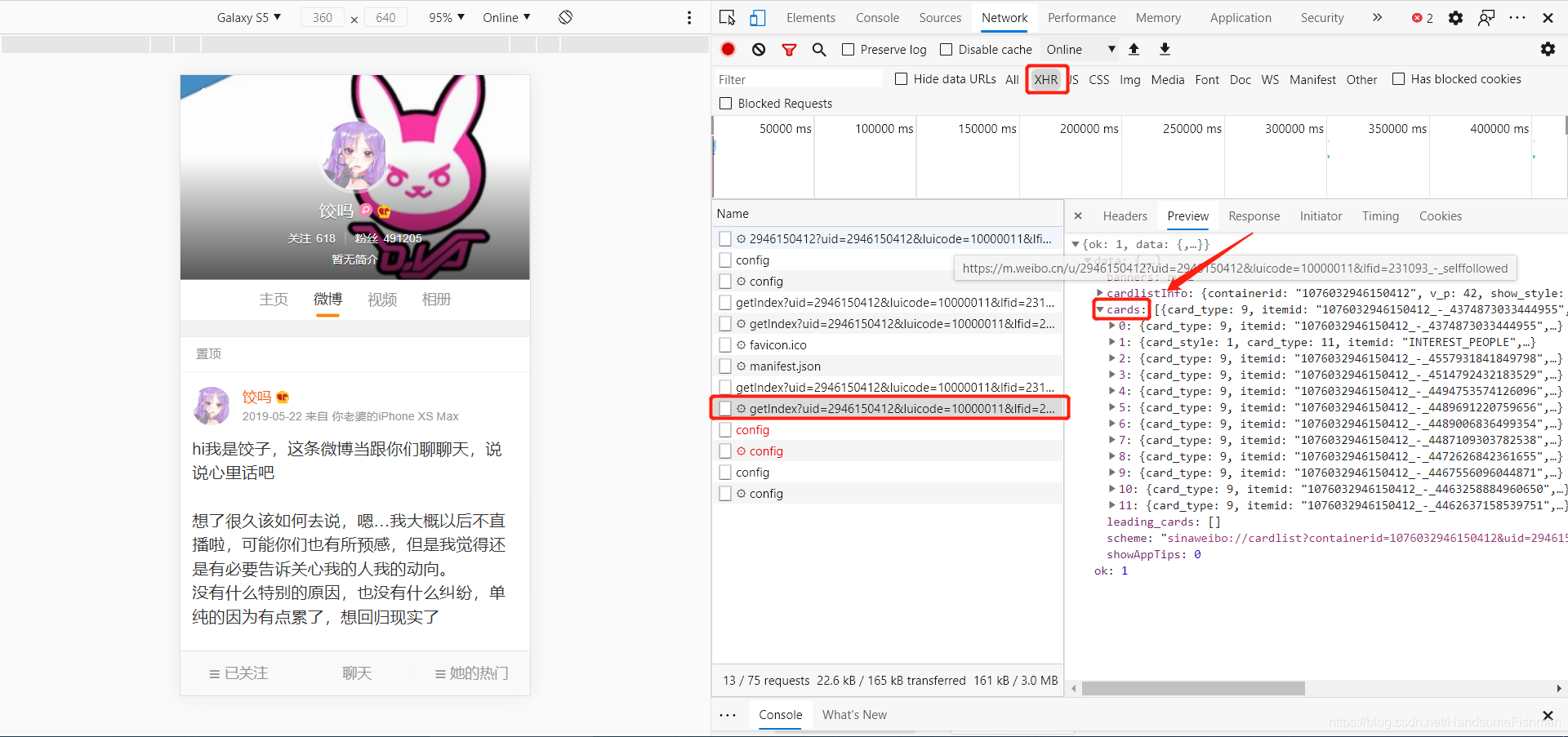
很明显可以看到crads下对应了多条数据,而其中的mblog下存放着对应微博的相关数据:
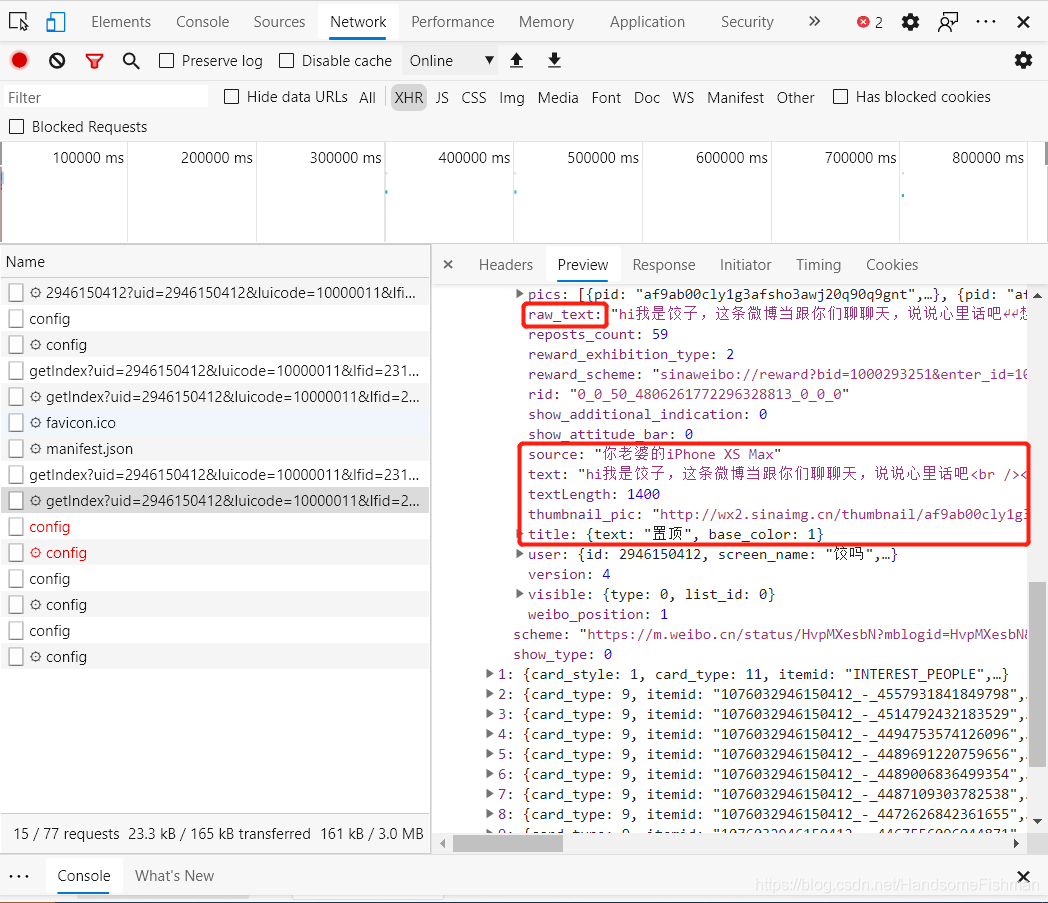
不要着急现在就去解析界面数据,先去看看下一页的加载,怎样去请求下一条数据:
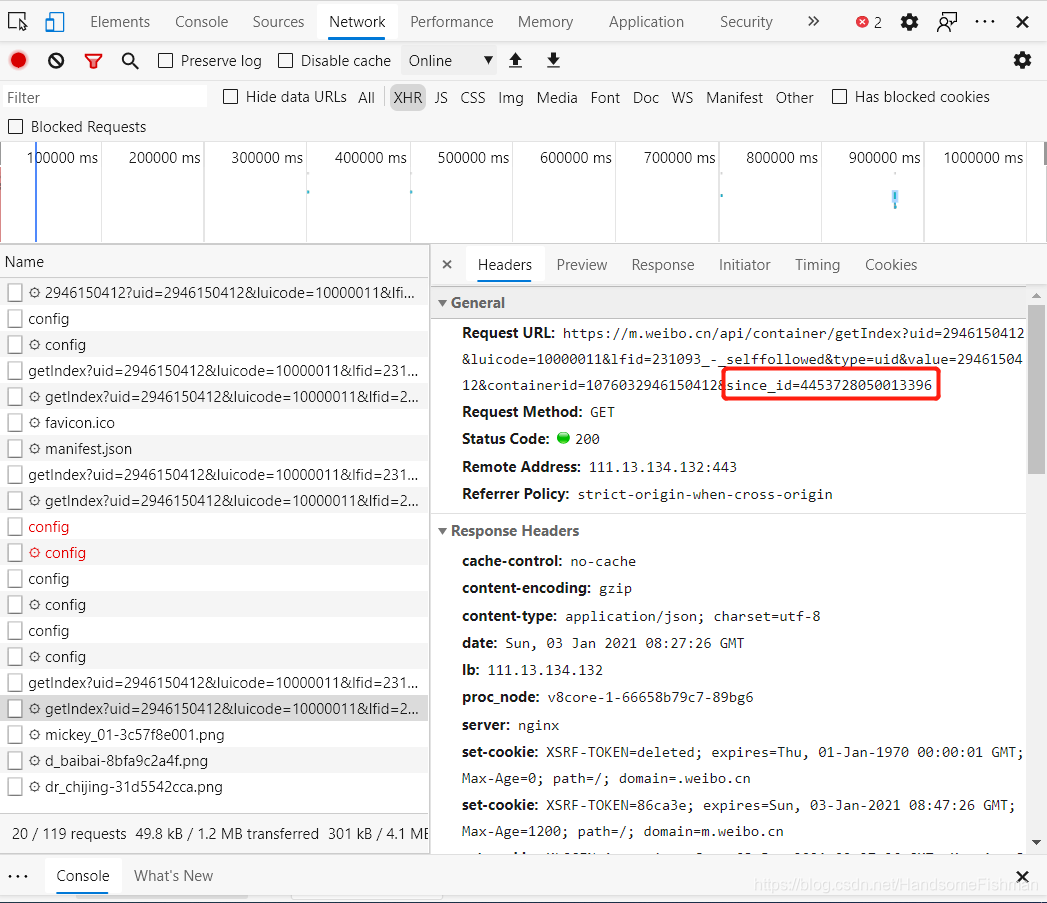
对比看到多出了一个since_id的数据,发现这个数据的来源是上一条json数据中的:
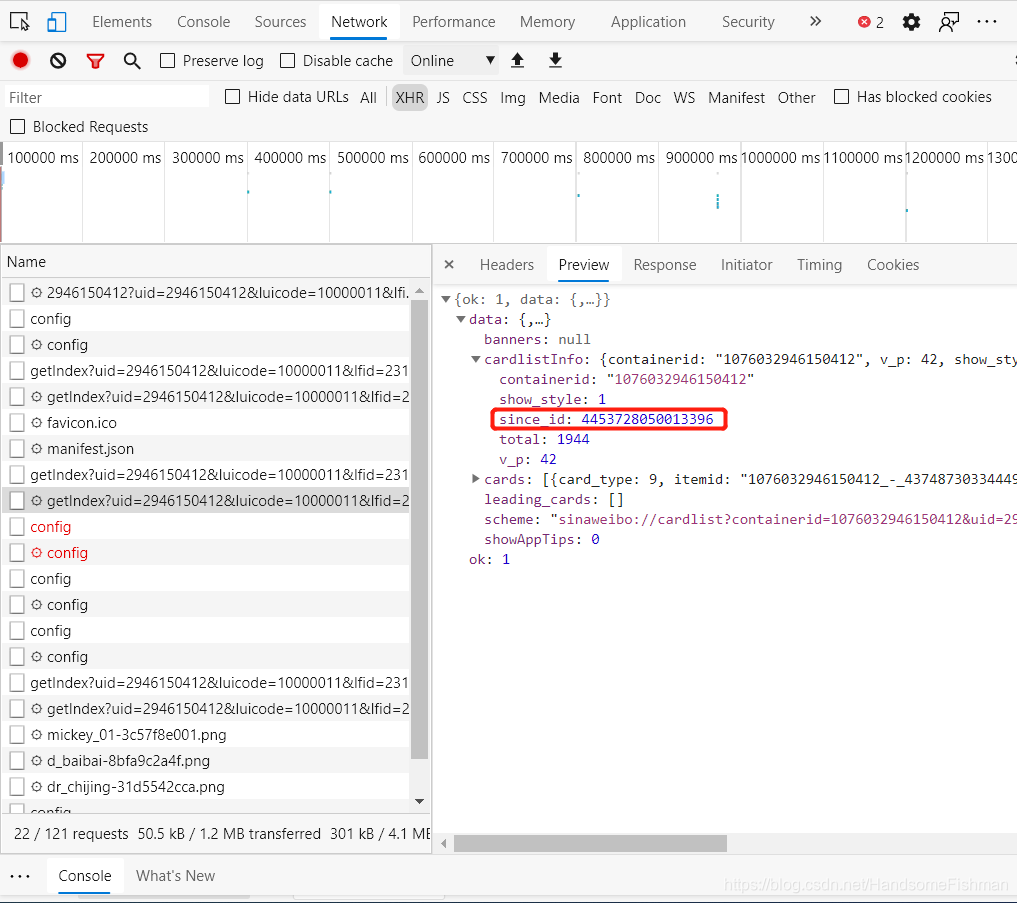
到这里我们的分析就结束了,接下来进行代码的编写。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import requests
from urllib.parse import urlencode
import random
headers = {
"Host": "m.weibo.cn",
"Referer": "https://m.weibo.cn/u/6816603335",
"user-agent": "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, "
"like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36 Edg/87.0.664.66 ",
"X-Requested-With": "XMXLHttpRequest"
}
base_url = 'https://m.weibo.cn/api/container/getIndex?'
proxy_pool = [{'HTTP': '27.206.178.75:9000'}, {'HTTP': '175.42.122.226:9999'}, {'HTTP': '175.42.158.31:9999'},
{'HTTP': '175.44.109.38:9999'}, {'HTTP': '42.238.91.46:9999'}, {'HTTP': '175.42.158.146:9999'},
{'HTTP': '123.160.69.171:9999'}, {'HTTP': '115.221.240.115:9999'}, {'HTTP': '183.166.110.5:9999'},
{'HTTP': '125.121.123.115:8888'}, {'HTTP': '117.64.237.222:1133'}, {'HTTP': '182.87.39.163:9000'},
{'HTTP': '120.79.184.148:8118'}, {'HTTP': '122.234.24.178:9000'}, {'HTTP': '175.42.158.74:9999'}]
weibo = {}
|
接下来我们进行函数的编写,封装两个函数,用来请求数据 和 解析数据。
请求参数如下:
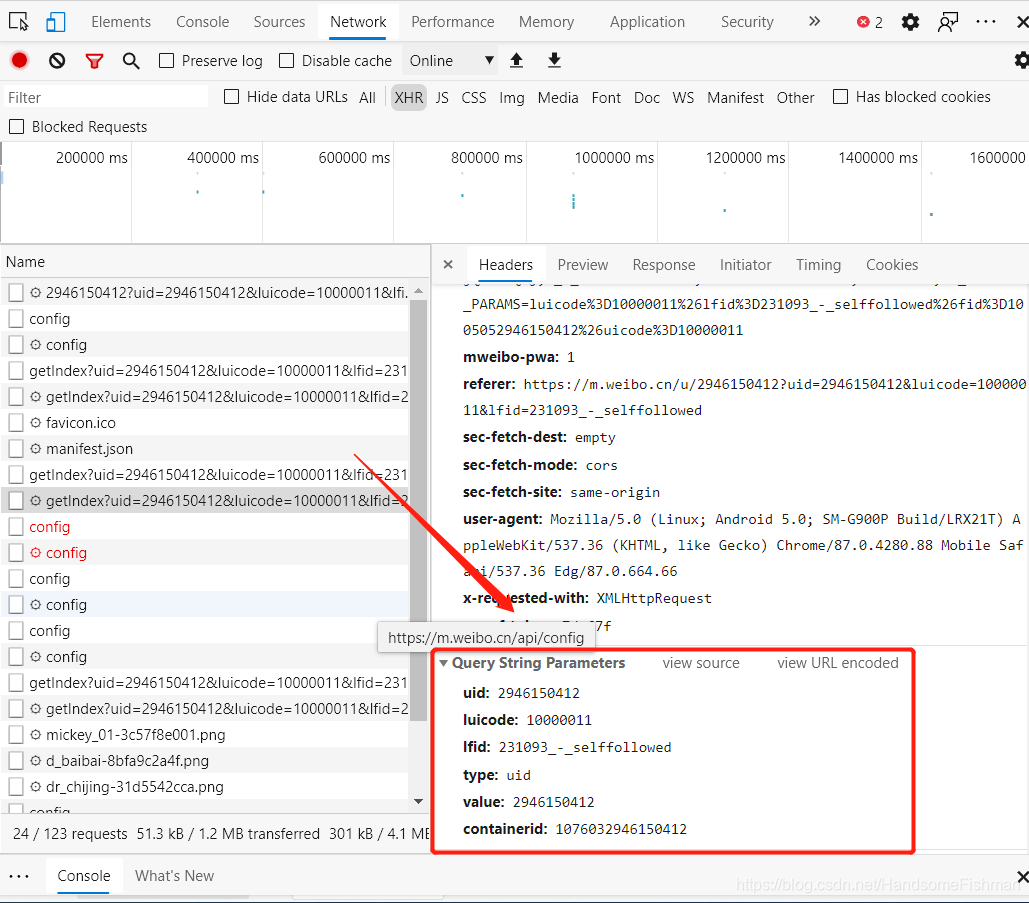
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
def get_page(since_id=None):
params = {
'uid': '2946150412',
'luicode': '10000011',
'lfid': '231093_-_selffollowed',
'type': 'uid',
'value': '2946150412',
'containerid': '1076032946150412',
'since_id': since_id
}
url = base_url + urlencode(params)
try:
response = requests.get(url=url, headers=headers, proxies=random.choice(proxy_pool))
if response.status_code == 200:
json = response.json()
next_since_id = json.get('data').get('cardlistInfo').get('since_id')
return json, next_since_id
except requests.ConnectionError as e:
print("错误:", e.args)
|
上面的函数会返回一个json对象和since_id的数据,json对象用来解析微博的对应信息,since_id为我们的下次爬取提供参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
def parse_page(json):
cards = json.get('data').get('cards')
for card in cards:
mblog = card.get('mblog')
if mblog:
weibo['source'] = mblog['source']
weibo['created_at'] = mblog['created_at']
weibo['raw_text'] = mblog['raw_text']
weibo['original_pic'] = mblog.get('original_pic')
pics = []
p = mblog.get('pics')
if p:
for pic in p:
pics.append(pic['url'])
weibo['pics'] = ' , '.join(pics)
yield weibo
|
最后封装一个函数调用上面的两个方法,并做到循环请求和解析的效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
def domain():
global return_data
for i in range(200):
if i == 0:
print("正在爬取第{}页....".format(i + 1))
return_data = get_page()
results = parse_page(return_data[0])
for res in results:
img = res.get('original_pic')
pics = res.get('pics')
if img is None:
img = "无"
if pics is None:
pics = "无"
with open('test.txt', 'a', encoding='utf8') as file:
file.write('时间:' + res['created_at'] + '\n' + '来源:' + res['source'] + '\n'
+ '内容:' + res['raw_text'] + '\n' + '附图链接地址:' + img + '\n'
+ '图床:' + pics + '\n' + '\n')
else:
print("正在爬取第{}页....".format(i + 1))
return_data = get_page(return_data[1])
results = parse_page(return_data[0])
for res in results:
img = res.get('original_pic')
pics = res.get('pics')
if img is None:
img = "无"
if pics is None:
pics = "无"
with open('test.txt', 'a', encoding='utf8') as file:
file.write('时间:' + res['created_at'] + '\n' + '来源:' + res['source'] + '\n'
+ '内容:' + res['raw_text'] + '\n' + '附图链接地址:' + img + '\n'
+ '图床:' + pics + '\n' + '\n')
|
运行结果如下:
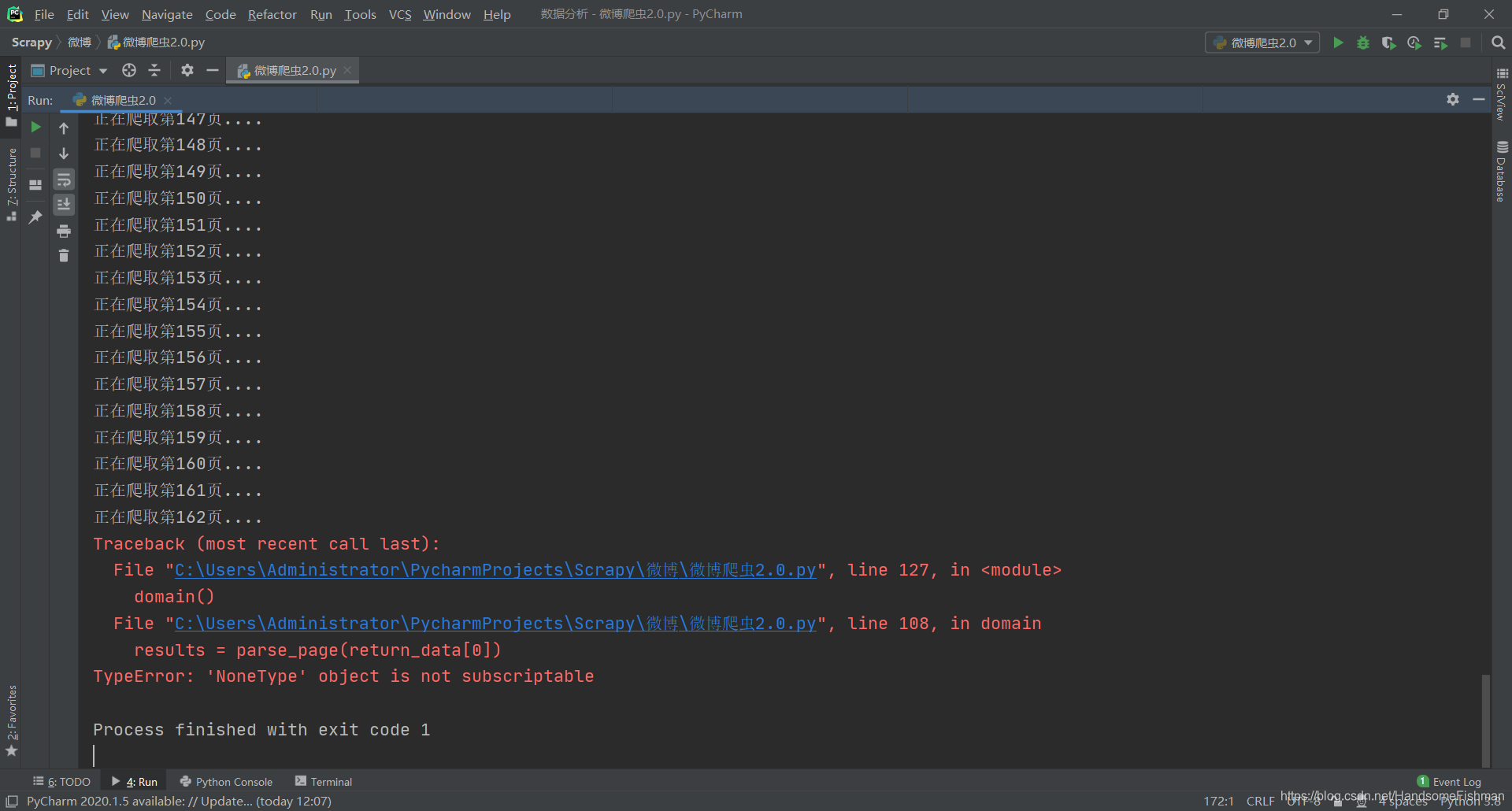
最后看一下我们的结果文件:
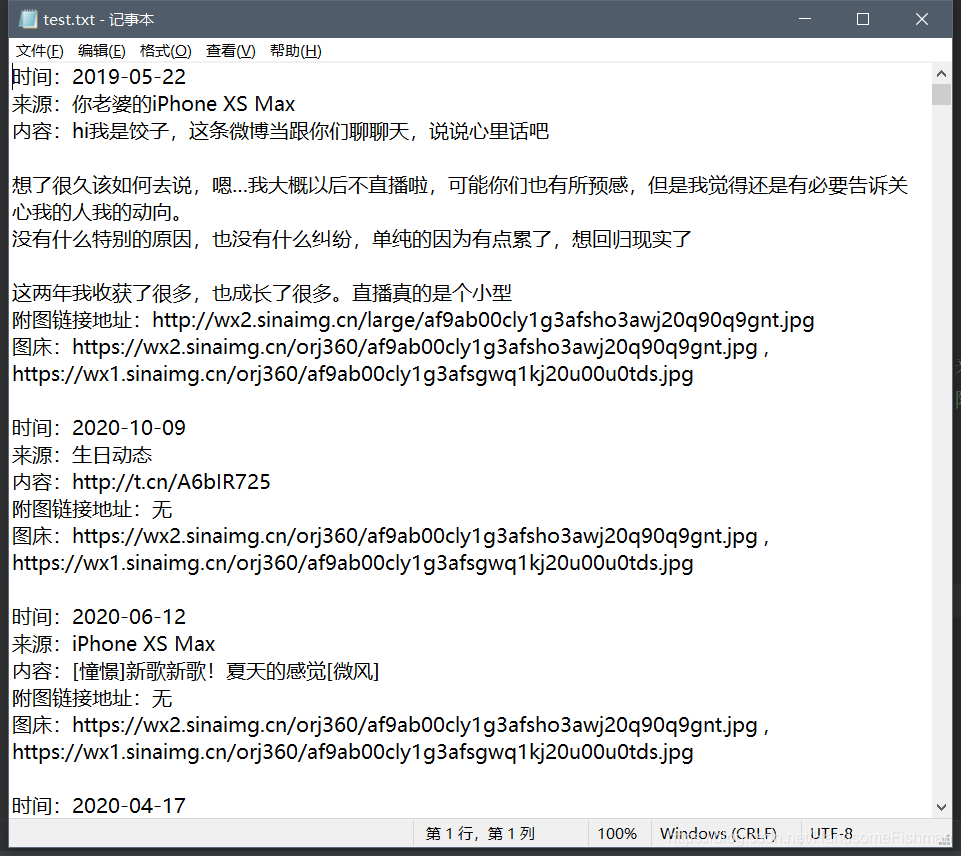
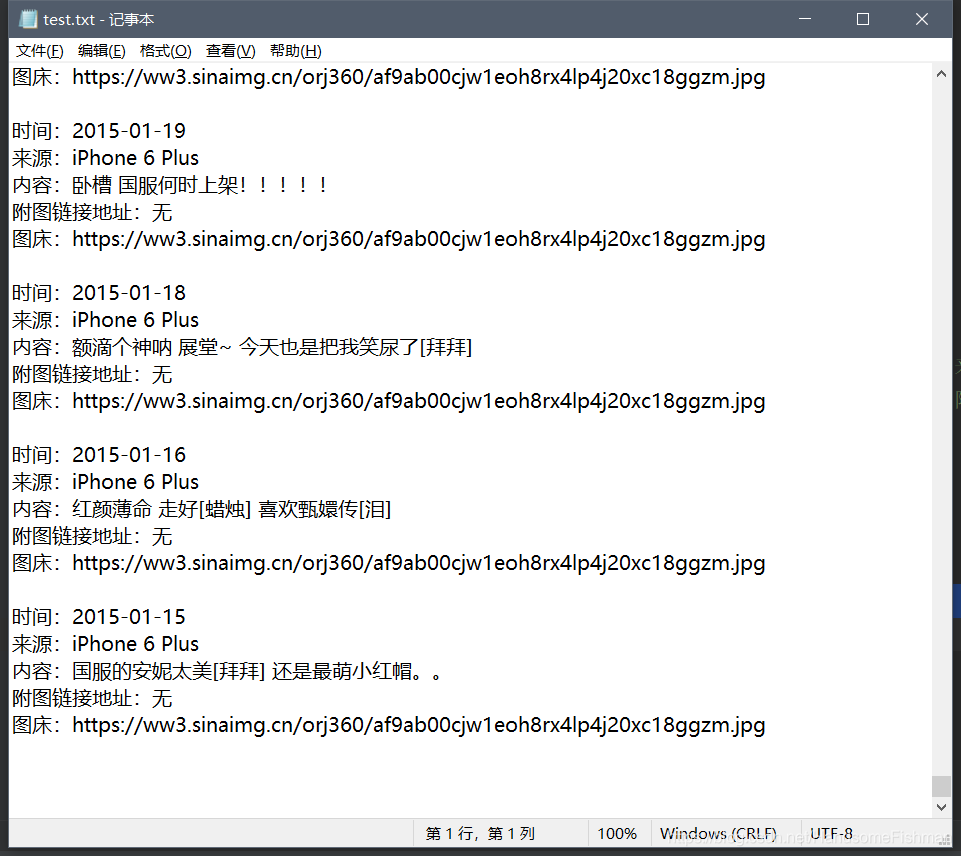
可以看到最早的2015年的微博也获取到了,对应的图片链接也是可以访问没有问题的。
注:案例仅供学习